A transzformer architektúra 2017-es bemutatása – a Google Brain kutatóinak „Attention is All You Need" címmel megjelent cikkével – az egyik legnagyobb áttörésnek számít a mesterséges intelligencia történetében. Az azóta eltelt években a transzformer szinte teljes egészében felváltotta az addig domináns visszacsatolásos neurális hálózatokat (RNN, LSTM) szövegfeldolgozási feladatokban, és a képfeldolgozásban is megkerülhetetlen architektúrává vált.
A transzformer előzményei és motivációja
Az 1990-es évektől az RNN (visszacsatolásos neurális hálózat) és annak fejlettebb változata, az LSTM (Long Short-Term Memory) dominálta a szövegfeldolgozást. Ezek a modellek szekvenciálisan dolgozzák fel az adatokat: minden pozíciónál az előző lépés kimenetét veszik figyelembe. Ez a szekvencialitás két komoly hátrányt jelent:
- A párhuzamos feldolgozás nehézkes, ami lassú tanítást eredményez.
- Hosszú szekvenciák esetén a korai tokenek információja fokozatosan elvész (eltűnő gradiens probléma).
A transzformer mindkét problémát megoldja azzal, hogy elhagyja a szekvenciális feldolgozást, és egy önfigyelmi mechanizmust alkalmaz, amely minden pozíciót közvetlenül kapcsolatba hozhat a szekvencia bármely másik pozíciójával.
Az önfigyelmi mechanizmus (Self-Attention)
Az önfigyelmi mechanizmus lényege, hogy a szekvencia minden egyes eleméhez (tokenéhez) három vektort rendel: egy kérdés vektort (Query, Q), egy kulcs vektort (Key, K) és egy érték vektort (Value, V). A figyelmi súlyokat a Q és K vektorok skaláris szorzataként számítják ki, majd ezzel súlyozzák a V vektorokat.
Ennek eredménye, hogy minden token „figyel" az összes többi tokenre, és az összefüggés erőssége tanult paraméterektől függ. Például egy „bank" szó esetén a modell megtanulja, hogy az előző mondatból a „folyó" szó erős kapcsolatban áll az aktuális „bank" előfordulással (ha folyópartról van szó), míg a „pénz" szóval gyenge a kapcsolat.
Az önfigyelmi mechanizmus lépései
- A bemeneti tokeneket vektorrá alakítják (embedding).
- Minden vektorból Q, K, V vektort számítanak tanult lineáris transzformációkkal.
- Figyelmi súlyok = softmax(QKT / √dk).
- Kimenet = figyelmi súlyok × V.
A transzformer felépítése
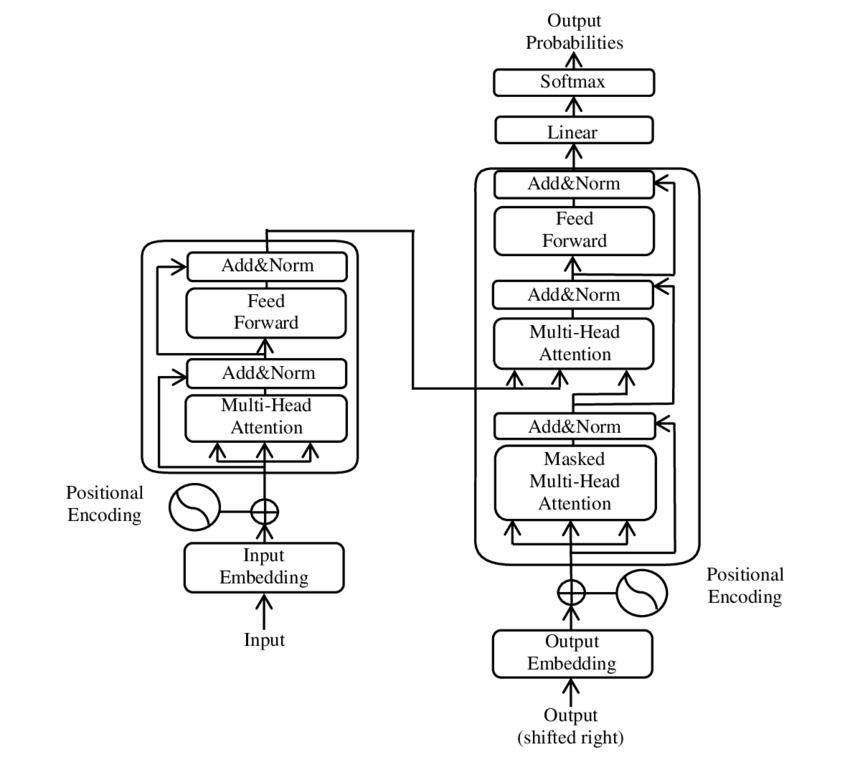
Az eredeti transzformer egy enkóder–dekóder architektúra. Az enkóder a bemeneti szekvenciát (pl. magyar mondatot) egy gazdag kontextuális reprezentációvá alakítja. A dekóder ebből a reprezentációból, valamint a saját eddig generált kimenetéből hozza létre a cél szekvenciát (pl. az angol fordítást).
Mindkét rész több ismétlődő blokkból áll, amelyek önfigyelmi réteget, keresztfigyelmi réteget (dekóderben) és előrecsatolt (feed-forward) hálózatot tartalmaznak. A rétegnormalizálás és a maradékkötések (residual connections) biztosítják a stabil tanítást még nagyon mély hálózatok esetén is.
Nagy nyelvi modellek (LLM)
A legtöbb jelenlegi nagy nyelvi modell a transzformer egy leszűkített, csak dekóder-részét alkalmazza (decoder-only). A GPT sorozat – a 2018-as GPT-1-től a GPT-4-ig – ilyen architektúrán alapul. A modell feladata, hogy egy adott szövegrészlet után meghatározza, mi a legvalószínűbb következő token.
A BERT (Bidirectional Encoder Representations from Transformers) ezzel szemben csak az enkóder részt alkalmazza, és kétirányúan – azaz a szöveg mindkét irányából – veszi figyelembe a kontextust. A BERT inkább megértési feladatokra (osztályozás, kérdés-válasz) alkalmas, mint generálásra.
A transzformer figyelmi mechanizmusa azt teszi lehetővé, hogy a modell egyetlen lépésben összefüggésbe hozza a szöveg tetszőleges távoli részeit – ami az emberi szövegértés egyik alapvető sajátossága.
Multimodális transzformer modellek
A transzformer architektúra nemcsak szövegre, hanem más típusú adatokra is alkalmazható. A Vision Transformer (ViT) képeket tokenizál képdarabokra (patch), majd a szöveg-transzformerekhez hasonló architektúrával dolgozza fel. A DALL-E 2, az Imagen és részben a Stable Diffusion is transzformer komponenseket (különösen a CLIP szövegenkódert) alkalmaz a szöveg–kép kapcsolat kiépítésére.
Ez a multimodális irány jelenleg a generatív MI egyik legaktívabb kutatási területe: a legjobb modellek egyszerre képesek szöveget, képet és hangot feldolgozni és generálni.